EgoAlpha
EgoAlpha🕯️ GPT2-finetuning内部构造
1.1 token化
对数据集进行处理部分是在encode.py内进行操作:
def main():
args = parser.parse_args()
enc = encoder.get_encoder(args.model_name, models_dir=args.models_dir)
print('Reading files')
chunks = load_dataset(enc, args.in_text, args.combine, encoding=args.encoding)
print('Writing', args.out_npz)
np.savez_compressed(args.out_npz, *chunks)
NLP预训练模型大都通过embedding 来表示词义,gpt中通过BPE(byte pair encoding)方法来进行分词。
以下是gpt2-finetuning中encoder.py内bpe的实现方法
# 将词表征为unicode代码
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a corresponding list of unicode strings.
The reversible bpe codes work on unicode strings.
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
This is a signficant percentage of your normal, say, 32K bpe vocab.
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
And avoids mapping to whitespace/control characters the bpe code barfs on.
"""
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8+n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
#bpe中将每个词进行分解
#例如将("hello")分解成("h""e","e""l",""l"l"...)
def get_pairs(word):
"""Return set of symbol pairs in a word.
Word is represented as tuple of symbols (symbols being variable-length strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
#开始训练前会调用encoder
class Encoder:
def __init__(self, encoder, bpe_merges, errors='replace'):
self.encoder = encoder
self.decoder = {v:k for k,v in self.encoder.items()}
self.errors = errors # how to handle errors in decoding
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v:k for k, v in self.byte_encoder.items()}
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges)))) #bpe_merges中表示为每种词的常用度排名
self.cache = {}
# Should haved added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")#一些特殊字符的操作,在后面会用到
#如果词在内部缓存中则直接返回。
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token)
#进行getpairs操作
pairs = get_pairs(word)
#词分不了pair则返回完整的词,词很短的情况下
if not pairs:
return token
#对pair词对进行操作
while True:
# 将输入的pairs 按照.bpe文件 (常用排名)排序 这里的pair 就是 55行提到 a b
# 找到最常用的哪个 pair float('inf') 表示无穷大 找不到的话 就返回无限大的值 以免被选上
bigram = min(pairs, key = lambda pair:
#MIN MAX 中key 相当于依据什么排序
self.bpe_ranks.get(pair, float('inf')))
# 组合不在bpe表格中 pairs中不能再拆了 循环结束
if bigram not in self.bpe_ranks:
break
# 拿到第一个词 第二个词
first, second = bigram
new_word = []
i = 0
# 查找子串
while i < len(word):
try:
j = word.index(first, i)# i指的是从第I个开始查找 #查找list.index(x,起始位置,终止位置) #从传入的word里 查找第一个单词
# 这里的意思是 因为pair 是无序的 要找到其在输入词中的顺序
new_word.extend(word[i:j])# 将这个子串 first=word[i:j] 放入new_word变量中
i = j
except:
new_word.extend(word[i:])# 当J越界时候 直接将 i: 切片放进去
break
# 这里的意思是 如果first 和 second 这两个是连着的话 加到new_word时候 是一个整体
if word[i] == first and i < len(word)-1 and word[i+1] == second:
new_word.append(first+second)
i += 2
else:
new_word.append(word[i])
i += 1
#递归操作
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
pairs = get_pairs(word)
word = ' '.join(word)
#将词放入缓存中
self.cache[token] = word
return word
# 不在self.encoder词典的词 编码过程
def encode(self, text):
bpe_tokens = []
#self.pat .findall text 的意思是从text 中 把self.pat这里pattern找出来 其实就是she's 变成 she s两个单词
for token in re.findall(self.pat, text):
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
#上面一句大致等价于 token = unicode(token, "utf-8") #将文字转成utf-8后 用self.byte_encoder——bytes_to_unicode()产生的dict 转回字符形式 然后将其连城字符串
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
#将拆完的词 在传入的embedding字典中查找,返回这个列表
return bpe_tokens
以上是encoder.py内容,encoder.py是为了在encode中将词进行bpe处理的方法。现在返回encode.py中的此行
chunks = load_dataset(enc, args.in_text, args.combine, encoding=args.encoding)
def load_dataset(enc, path, combine, encoding=None):
paths = []
if os.path.isfile(path):
# Simple file
paths.append(path)
elif os.path.isdir(path):
# Directory
for (dirpath, _, fnames) in os.walk(path):
for fname in fnames:
paths.append(os.path.join(dirpath, fname))
else:
# Assume glob
paths = glob.glob(path)
token_chunks = []
raw_text = ''
for path in tqdm.tqdm(paths):
if path.endswith('.npz'):
# Pre-encoded
with np.load(path) as npz:
for item in npz.files:
token_chunks.append(npz[item])
else:
# Plain text
with open(path, 'r', encoding=encoding) as fp:
raw_text += fp.read()
if len(raw_text) >= combine:
tokens = np.stack(enc.encode(raw_text))
token_chunks.append(tokens)
raw_text = ''
else:
raw_text += '<|endoftext|>'
if raw_text:
tokens = np.stack(enc.encode(raw_text))
token_chunks.append(tokens)
return token_chunks
1.2 model函数、
首先是model的主体model函数如下:
#X和past的输入情况:
#X是语言模型输入,past是已生成上文的状态。
#训练时,X为一组训练数据[2],past为空。
#条件生成初始阶段,X为条件语句,past为空
#无条件生成初始阶段,X为[end],past为空
#生成过程中,X为上一次生成的词语,past为之前所有K和V。
def model(hparams, X, past=None, scope='model', reuse=tf.AUTO_REUSE):
with tf.variable_scope(scope, reuse=reuse):
results = {}
batch, sequence = shape_list(X)
wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.01))
wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd],
initializer=tf.random_normal_initializer(stddev=0.02)) #vte vpe 词向量矩阵 wte词语嵌入矩阵 wpe位置嵌入矩阵
past_length = 0 if past is None else tf.shape(past)[-2] #已生成上文的长度
h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length)) #由输入x提供的信息 vte与vpe加和而来 shape为[批次大小,输入长度,嵌入维度]
# Transformer
presents = []
pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer
assert len(pasts) == hparams.n_layer
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams) #h最终的shape是[batch, seq, embd]
if layer == 10:
tf.add_to_collection('checkpoints', h)
presents.append(present)
results['present'] = tf.stack(presents, axis=1)
h = norm(h, 'ln_f') #将h展平成[batch*seq,embd],用矩阵乘法乘以word embd转换矩阵(shape=[vocab,embd]),最后再reshape,得到最终的输出logits
# Language model loss. Do tokens <n predict token n?
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])
#
logits = tf.matmul(h_flat, wte, transpose_b=True)
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab])
results['logits'] = logits
return results
首先看第一部分
pythonresults = {} batch, sequence = shape_list(X) wpe = tf.get_variable('wpe', [hparams.n_ctx, >hparams.n_embd], >initializer=tf.random_normal_initializer(stddev=0.01)) wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.02)) #vte vpe 词向量矩阵 wte词语嵌入矩阵 wpe位置嵌入矩阵 past_length = 0 if past is None else tf.shape(past)[-2] #已生成上文的长度 h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length))
首先将每个语句分解成两个权重矩阵,wpe和wte,也就是单词的词嵌入向量和单词位置编码。 

处理完embedding后,将这些矩阵向上发到block块中,
python
presents = [] pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer assert len(pasts) == hparams.n_layer for layer, past in enumerate(pasts): h, present = block(h, 'h%d' % layer, past=past, hparams=hparams) #h最终的shape是[batch, seq, embd] if layer == 10: tf.add_to_collection('checkpoints', h) presents.append(present) results['present'] = tf.stack(presents, axis=1)
现在来看block块,每个block可以看做是数据处理的一层,它包含了自注意力机制,前馈神经网络以及残差连接。 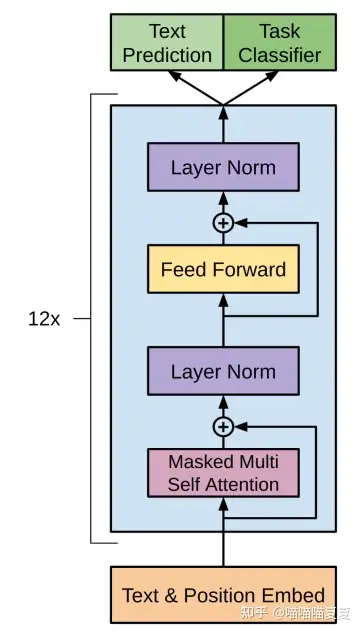
def block(x, scope, *, past, hparams):
with tf.variable_scope(scope):
nx = shape_list(x)[-1]
a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams) #取embedding维度为nx和做Attention。注意这里在做Attention层之前先对x做normalization
x = x + a #残差操作,这里的'+'是element-wise plus。 此时x=a=[batch,seq,embedding],加和之后依然是[batch,seq,embedding]。
m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams) #m是经过mlp进一步提取的特征。
x = x + m #将mlp得到的信息m残差加和到已有信息x。
return x, present #返回最终结果 + present [batch, seq, embd]
block中将前一层的输出作为输入首先进行了已知信息x与注意力机制下的输出a残差相加,其中自注意力操作如下:
1.为每个单词创建query,key,value 向量
2.对于每个输入token,使用其query向量对其他所有的token的key向量进行评分,获得注意力分数。
3.将value向量乘以上一步得到的注意力分数,进行相加。
其中q,k,v向量分别代表着:
query:是当前单词的表示形式,用于对所有其他单词(key)进行评分,我们只需要关注当前正在处理的token的query。
Key:可以看做是序列中所有单词的标签,是在我们找相关单词时候的对照物。
Value:单词的实际表示,一旦我们对每个单词的相关度打分之后,我们就要对value进行相加表示当前正在处理的单词的value。
1.2.1自注意力操作
第一步:创建query,key,value向量  代码中对应操作是:
代码中对应操作是:
c = conv1d(x, 'c_attn', n_state*3)
q, k, v = map(split_heads, tf.split(c, 3, axis=2))
卷积方法是:
#该函数将x原有的nx个feature线性变换为nf个feature,可以看作一维卷积,也可以看作一个Linear层。
#nx是x目前feature数,start是其余shape。shape_list函数是将x的shape以列表返回。
#w是第一层linear的参数,定义为[1,原feature数,新feature数的变量,并以正态分布初始化。
#b是第一层linear的偏移值,定义为[新feature]数的变量,并以常值0初始化。
#c是线性变换的结果,这句话等价于C=WX+B
#最外层tf.reshape的目的是将结果转化为正确的三维shape,start+[nf]是列表的拼接,结合前面start的定义,其实就是将最后一维nx换为nf。
#内层先reshape为二维,做矩阵乘,加上偏置。
def conv1d(x, scope, nf, *, w_init_stdev=0.02):
with tf.variable_scope(scope):
*start, nx = shape_list(x)
w = tf.get_variable('w', [1, nx, nf], initializer=tf.random_normal_initializer(stddev=w_init_stdev))
b = tf.get_variable('b', [nf], initializer=tf.constant_initializer(0))
c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, start+[nf])
return c
第二步:计算注意力分数,通过query和key向量,将第一个token的query与其他token的key向量点乘,得到每一个token的注意力分数  第三步:求和,对于每一个token将上一步得到的注意力分数,与value向量相乘,再累加softmax化得到最后的注意力分数占比
第三步:求和,对于每一个token将上一步得到的注意力分数,与value向量相乘,再累加softmax化得到最后的注意力分数占比  这两步的代码在multhead_attn方法中体现,该代码会在之后进行解释。
这两步的代码在multhead_attn方法中体现,该代码会在之后进行解释。
1.2.2 带掩码的自注意力操作
以上是transformer中的自注意力机制,需要注意的是gpt用的是带masked的自注意力,它与普通的自注意力不同的是,每个正在处理的token,后边的token的注意力得分为0,即只会关注当前token前面的输入句子
例如,输入序列“robot must obey orders”中。每个单词作为一个token,对于处理序列批量大小为4的情况下,模型将整个序列作为一个batch进行处理。  此时token无法直接计算注意力分数,因此需要用token对应的query与key进行计算
此时token无法直接计算注意力分数,因此需要用token对应的query与key进行计算  完成乘法运算后,加上mask矩阵来屏蔽掉当前还为输入的词,通常是将mask矩阵设置成上三角矩阵,屏蔽位置的数值为非常大的负数。
完成乘法运算后,加上mask矩阵来屏蔽掉当前还为输入的词,通常是将mask矩阵设置成上三角矩阵,屏蔽位置的数值为非常大的负数。  再进行softmax化,得到注意力分数:
再进行softmax化,得到注意力分数:  上表中可以理解为,当只输入一个单词robot时,robot的注意力得分为1,输入第二个词must时,robot注意力得分为0.48,must得分为0.52...可以看到,每个词的后边的词注意力得分皆为0
上表中可以理解为,当只输入一个单词robot时,robot的注意力得分为1,输入第二个词must时,robot注意力得分为0.48,must得分为0.52...可以看到,每个词的后边的词注意力得分皆为0
在代码中,上述部分操作在mask_attn_weights中,这部分是设置掩码的权重矩阵。
1.2.3 gpt2中的mask self attention
现在假设用gpt2模型来进行预测任务,模型在每次迭代后都会新增一个词,此时为了增加模型处理效率,gpt2中不是简单的每输入一个token就对前面所有token进行点乘注意力计算,它会对前面的token key和value向量进行保存,从而在迭代中提取 

 而gpt2中的token的qkv向量是通过自注意力层乘以权值矩阵得到这个token的query,key,value的拼接向量。
而gpt2中的token的qkv向量是通过自注意力层乘以权值矩阵得到这个token的query,key,value的拼接向量。 

 在通过划分多头来得到每个头的value评分。
在通过划分多头来得到每个头的value评分。 

在通过每个value与它的注意力分数相乘相加,得到这个多头的自注意力结果。 

 最后通过合并多头得到最终结果。
最后通过合并多头得到最终结果。 
def attn(x, scope, n_state, *, past, hparams):
assert x.shape.ndims == 3 # Should be [batch, sequence, features]
assert n_state % hparams.n_head == 0
if past is not None:
assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v]
def split_heads(x):
# From [batch, sequence, features] to [batch, heads, sequence, features]
return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3]) #首先应用split_states,将x转换为[batch,seq,head,feature]。然后使用tf.transpose,将原有维度重排为[batch,head,seq,feature],也就是将第一维和第二维交换位置。
#首先将A转化为[batch,输入长度,head,feature],依然是通过tf.transpose交换中间两维实现的。
def merge_heads(x):
# Reverse of split_heads
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
def mask_attn_weights(w):
# w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst. nd为输入长度,ns为总长度。
_, _, nd, ns = shape_list(w) #Gpt-2等一系列Transformer生成模型使用masked attention,主要是为了避免模型在生成第i个词时使用i之后的词语, 因为在实际预测时后面的词是不可知的。
b = attention_mask(nd, ns, dtype=w.dtype) #b为非0即1的mask矩阵,后面会将b与w相乘。
b = tf.reshape(b, [1, 1, nd, ns]) #将返回的mask矩阵reshape为四维[11],然后与权重矩阵做element-wise的乘法。后面减去1e10*(1-b),当b为1时无效果,当b为0时,等于减去1e10,一个很大的值,导致值变为-10e,也就导致softmax之后权重变为0.
w = w*b - tf.cast(1e10, w.dtype)*(1-b)
return w #该函数返回mask之后的权重矩阵W,准确地说,是将权重矩阵第i行的不可attend列置为0。
def multihead_attn(q, k, v):
# q, k, v have shape [batch, heads, sequence, features]
w = tf.matmul(q, k, transpose_b=True) #matmul中transpose_b参数意味着乘之前将K转置。
w = w * tf.rsqrt(tf.cast(shape_list(v)[-1], w.dtype)) #注意Q=[batch,head,输入长度,feature],K=[batch,head,总长度,feature],matmul对最后二维进行,其实也就是Q的feature和K的feature做点积,W=[batch,head,输入长度,总长度],表示V的得分。
w = mask_attn_weights(w) #参考上面maskattnweight
w = softmax(w) #将权重矩阵做一次softmax,将权重归一为[0,1]之间且和为1。
a = tf.matmul(w, v) #此时W=[batch,head,输入长度,总长度],V=[batch,head,总长度,feature]得到A=[batch,head,输入长度,feature],这就是Attention机制所提取的特征。
return a
with tf.variable_scope(scope):
c = conv1d(x, 'c_attn', n_state*3) #将x通过一次一维卷积,从embedding中提取n_state*3个特征,gpt-2中n_state=embedding。此时c=[batch,seq,embedding*3]
q, k, v = map(split_heads, tf.split(c, 3, axis=2))#使用tf.split将特征分给q,k,v。此时Q=K=V=[batch,seq,embedding]
present = tf.stack([k, v], axis=1) #present是tf.stack完成的k和v的堆叠,这一项会作为返回值返回,并且与之前的状态拼接,作为self-attention的对象。
if past is not None:
pk, pv = tf.unstack(past, axis=1)
k = tf.concat([pk, k], axis=-2)
v = tf.concat([pv, v], axis=-2) #这一段就是从之前的状态分出k和v,将其拼接到当前的k和v上。拼接之前k=v=[batch,head,当前长度,feature],在拼接之后k=v=[batch,head,已生成长度+当前长度,feature]
a = multihead_attn(q, k, v) #a是attn层的输出,也就是之后的h,是Q和K对的V加权和
a = merge_heads(a) #合并多头,这是分解多头的逆过程。
a = conv1d(a, 'c_proj', n_state) #最后的线性变换。
return a, present
在注意力操作中,会对输入张量进行以下几个操作: 首先对词向量进行掩码操作:
def attention_mask(nd, ns, *, dtype):
i = tf.range(nd)[:,None]
j = tf.range(ns)
m = i >= j - ns + nd
return tf.cast(m, dtype)
在分解多头以及合并时,需要用到split_states,以及merge_states函数:
#该程序将x的最后一维分解为二维,即分出多头维
def split_states(x, n):
"""Reshape the last dimension of x into [n, x.shape[-1]/n]."""
*start, m = shape_list(x)
return tf.reshape(x, start + [n, m//n])
#将最后两维reshape为一维,也就是将head个feature顺序堆叠。
#此时A=[batch,输入长度,head*feature=embedding],
def merge_states(x):
"""Smash the last two dimensions of x into a single dimension."""
*start, a, b = shape_list(x)
return tf.reshape(x, start + [a*b])
在操作完注意力机制后,然后对新结果提取特征在附着到x中,全连接神经网络的输入是自注意力层的输出,用于处理自注意力子层得到的token的新的表示,这个新的表示包含了原始token及其上下文的信息。  第一层将向量转换成模型大小的多被
第一层将向量转换成模型大小的多被  第二层将第一层的结果再投射回模型的维度。 mlp的操作如下:
第二层将第一层的结果再投射回模型的维度。 mlp的操作如下:
def mlp(x, scope, n_state, *, hparams): #n_state表示第一层线性变换的特征维度。
with tf.variable_scope(scope):
nx = shape_list(x)[-1]
h = gelu(conv1d(x, 'c_fc', n_state))
h2 = conv1d(h, 'c_proj', nx) #线性变换到n_state维,gelu激活,再变换回nx维。
return h2
以上是block部分,我们继续看model部分,在将词向量输入到block中并提取结果后,会进行如下操作:
presents = []
pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer
assert len(pasts) == hparams.n_layer
for layer, past in enumerate(pasts):
h, present = block(h, 'h%d' % layer, past=past, hparams=hparams) #h最终的shape是[batch, seq, embd]
if layer == 10:
tf.add_to_collection('checkpoints', h)
presents.append(present)
results['present'] = tf.stack(presents, axis=1)
h = norm(h, 'ln_f') #将h展平成[batch*seq,embd],用矩阵乘法乘以word embd转换矩阵(shape=[vocab,embd]),最后再reshape,得到最终的输出logits
# Language model loss. Do tokens <n predict token n?
h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd])
#
logits = tf.matmul(h_flat, wte, transpose_b=True)
logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab])
results['logits'] = logits
return results
这部分的操作是将结果从三维的词向量展平成二维,方便后续进行字典查询以及概率表示。
1.3 开始训练
处理完token后,将数据集进行训练,首先是各种参数设置:例如batch数量batch_size,学习率learning_rate,优化器optimizer等,以及模型选择,数据集选择等。这些参数均在parser中进行修改。
def main():
args = parser.parse_args()
enc = encoder.get_encoder(args.model_name, models_dir=args.models_dir)
hparams = model.default_hparams() ## 读取默认参数
with open(os.path.join('models', args.model_name, 'hparams.json')) as f: ## 预训练中的模型参数
hparams.override_from_dict(json.load(f)) ## 参数重写
if args.sample_length > hparams.n_ctx: ## 这里要求我们设置的一个句子的长度不能大于预训练模型的
raise ValueError(
"Can't get samples longer than window size: %s" % hparams.n_ctx)
之后是训练集验证集构建:
with tf.Session() as sess:
# Fully static shape required to make memory accounting in
# twremat accurate.
train_context = tf.placeholder(tf.int32, [args.batch_size, 1024]) ## 占位
train_context_in = randomize(train_context, hparams, args.noise) ## 设置为输入
train_output = model.model(hparams=hparams, X=train_context_in) ### 调用gpt-2的model
train_loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=train_context[:, 1:], logits=train_output['logits'][:, :-1]))
if args.val_every > 0: ## 验证数据构建
val_context = tf.placeholder(tf.int32, [args.val_batch_size, None])
val_output = model.model(hparams=hparams, X=val_context)
val_loss = tf.reduce_mean( #移轴平均值
tf.nn.sparse_softmax_cross_entropy_with_logits( #计算误差 损失函数
labels=val_context[:, 1:], logits=val_output['logits'][:, :-1]))
val_loss_summary = tf.summary.scalar('val_loss', val_loss)
其中会在训练集中添加随机噪音:
def randomize(context, hparams, p): ## 随机mask、添加noise
if p > 0:
mask = tf.random.uniform(shape=tf.shape(context)) < p
noise = tf.random.uniform(shape=tf.shape(context), minval=0, maxval=hparams.n_vocab, dtype=tf.int32)
return tf.where(mask, noise, context)
else:
return context
构建完验证集后进行需要训练更新的参数:
all_vars = [v for v in tf.trainable_variables() if 'model' in v.name] ## 获得所有要更新的参数; tf.trainable_variables () 指的是需要训练的变量
train_vars = [v for v in all_vars if '/h' in v.name] if args.only_train_transformer_layers else all_vars ## 仅仅训练/h里的参数
选择优化器以及算法:
if args.optimizer == 'adam':
print('Using Adam optimizer', file=sys.stderr)
opt = tf.train.AdamOptimizer(learning_rate=args.learning_rate)
elif args.optimizer == 'sgd':
print('Using SGD optimizer', file=sys.stderr)
opt = tf.train.GradientDescentOptimizer(learning_rate=args.learning_rate)
else:
exit('Bad optimizer:', args.optimizer)
if args.memory_saving_gradients:
if tf.VERSION >= '2':
exit('Memory saving gradients are not supported in tensorflow 2.x')
import memory_saving_gradients
opt_grads = memory_saving_gradients.gradients(train_loss, train_vars) ## 通过train_loss 对train_vars求梯度
elif args.twremat:
import tfremat
opt_grads = tf.gradients(train_loss, train_vars)
(train_loss, opt_grads) = tfremat.tf_remat((train_loss, opt_grads), memlimit=args.twremat_memlimit)
else:
opt_grads = tf.gradients(train_loss, train_vars)
进行训练:
opt_grads = list(zip(opt_grads, train_vars))
opt_apply = opt.apply_gradients(opt_grads) ## 进行梯度下降
summary_loss = tf.summary.scalar('loss', train_loss) # 用来显示标量信息
summary_lr = tf.summary.scalar('learning_rate', args.learning_rate)
summaries = tf.summary.merge([summary_lr, summary_loss])
summary_log = tf.summary.FileWriter(
os.path.join(CHECKPOINT_DIR, args.run_name))
#保存模型
saver = tf.train.Saver(
var_list=all_vars,
max_to_keep=5,
keep_checkpoint_every_n_hours=2)
sess.run(tf.global_variables_initializer()) ## 初始化变量
保存点和导入预训练的模型:
if args.restore_from == 'latest':
ckpt = tf.train.latest_checkpoint(
os.path.join(CHECKPOINT_DIR, args.run_name))
if ckpt is None:
# Get fresh GPT weights if new run.
ckpt = tf.train.latest_checkpoint(
os.path.join('models', args.model_name))
elif args.restore_from == 'fresh':
ckpt = tf.train.latest_checkpoint(
os.path.join('models', args.model_name)) ## 导入预训练模型
else:
ckpt = tf.train.latest_checkpoint(args.restore_from)
print('Loading checkpoint', ckpt)
saver.restore(sess, ckpt) ## 模型恢复 saver.restore(sess,数据路径)
1.4 样例生成
在gpt2-fintuning中 进行训练时会进行样例生成,样例生成代码在sample.py中
候选tokens 可以根据temperature参数大小来控制生成文本的多样性和创造力。温度越高,生成的文本越多样化,但也可能会导致生成的文本不太准确或不连贯。温度越低,生成的文本则越接近训练数据,但也可能会导致生成的文本过于保守和重复 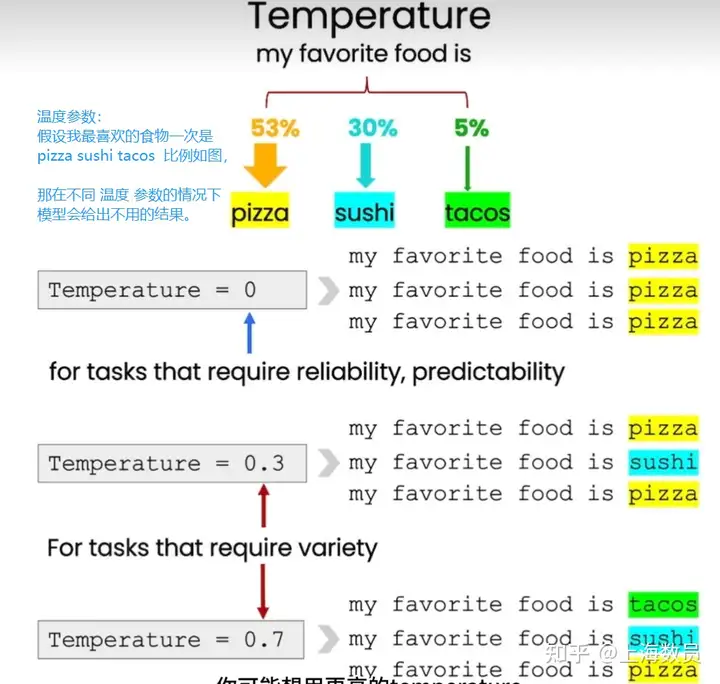
字词的选择是根据top_p 以及 top_k 进行选取,top_p以及top_k 均是用来防止生成结果进入循环 其中top_k 参数用来选取候选tokens中概率前k个tokens做为下一步候选tokens
def top_k_logits(logits, k): ## 计算top_k
if k == 0:
# no truncation
return logits
def _top_k():
values, _ = tf.nn.top_k(logits, k=k)
min_values = values[:, -1, tf.newaxis]
return tf.where(
logits < min_values,
tf.ones_like(logits, dtype=logits.dtype) * -1e10,
logits,
)
return tf.cond(
tf.equal(k, 0),
lambda: logits,
lambda: _top_k(),
)
top_p方法 用来选取候选tokens中概率累加达到p阈值的前几个tokens做为下一步候选tokens
ef top_p_logits(logits, p): ### 计算top_p, 等于1时相当于没计算
with tf.variable_scope('top_p_logits'):
logits_sort = tf.sort(logits, direction='DESCENDING')
probs_sort = tf.nn.softmax(logits_sort)
probs_sums = tf.cumsum(probs_sort, axis=1, exclusive=True)
logits_masked = tf.where(probs_sums < p, logits_sort, tf.ones_like(logits_sort)*1000) # [batchsize, vocab]
min_logits = tf.reduce_min(logits_masked, axis=1, keepdims=True) # [batchsize, 1] # 按照indices的格式从sorted_logits中抽取切片
return tf.where( # 若condition=True,则返回对应X的值,False则返回对应的Y值。
logits < min_logits,
tf.ones_like(logits, dtype=logits.dtype) * -1e10,
logits,
)
再了解完输出参数后,来看gpt2-finetuning的样例输出过程:
def sample_sequence(*, hparams, length, start_token=None, batch_size=None, context=None, temperature=1, top_k=0, top_p=0.0):
if start_token is None:
assert context is not None, 'Specify exactly one of start_token and context!'
else:
assert context is None, 'Specify exactly one of start_token and context!'
context = tf.fill([batch_size, 1], start_token) #value=1 fill() 起始token为开头
def step(hparams, tokens, past=None):
lm_output = model.model(hparams=hparams, X=tokens, past=past, reuse=tf.AUTO_REUSE)
logits = lm_output['logits'][:, :, :hparams.n_vocab]
presents = lm_output['present']
presents.set_shape(model.past_shape(hparams=hparams, batch_size=batch_size))
return {
'logits': logits,
'presents': presents,
}
with tf.name_scope('sample_sequence'):
def body(past, prev, output):
next_outputs = step(hparams, prev, past=past) # shape=(1, ?, 50257)
logits = next_outputs['logits'][:, -1, :] / tf.to_float(temperature) ## 只要最后一个输出的值(可能值的概率向量)
if top_p > 0.0:
logits = top_p_logits(logits, p=top_p)
else:
logits = top_k_logits(logits, k=top_k) ## [00,00,0.2,00,1,] 概率
samples = tf.multinomial(logits, num_samples=1, output_dtype=tf.int32) #logits是一个二维张量,num_samples指的是采样的个数。其实很好理解,我们生成每个时刻的 logits 时,输出维度应该是 [ batch_size, vocab_size ] 形式的,代表着该时刻,每一个batch对应的词典中各词汇生成的概率。tf.multinomial() 将按照该概率分布进行采样,返回的值是 logits 第二维上的 id,也就是我们需要的字典的 id。
return [
next_outputs['presents'] if past is None else tf.concat([past, next_outputs['presents']], axis=-2), # present 是每一层的[k,v]
samples,
tf.concat([output, samples], axis=1)
]
past, prev, output = body(None, context, context)
def cond(*args):
return True
_, _, tokens = tf.while_loop( # 循环 loop_vars既是输出值也是下次循环的输入值
cond=cond, body=body,
maximum_iterations=length - 1,
loop_vars=[
past,
prev,
output
],
shape_invariants=[
tf.TensorShape(model.past_shape(hparams=hparams, batch_size=batch_size)),
tf.TensorShape([batch_size, None]),
tf.TensorShape([batch_size, None]),
],
back_prop=False,
)
return tokens
1.5 token选取可视化翻译
以下内容描述如何将可视化隐藏层并找到gpt2选取token的逻辑
翻译自:Finding the Words to Say: Hiddent State Visualizations for Language Models https://jalammar.github.io/hidden-states/
代码实现:https://colab.research.google.com/github/jalammar/ecco/blob/main/
可视化效果:当模型生成句子时,将每一个输出的词在该层中的分数排序列出,并用颜色深浅来代表它的分数排行大小. 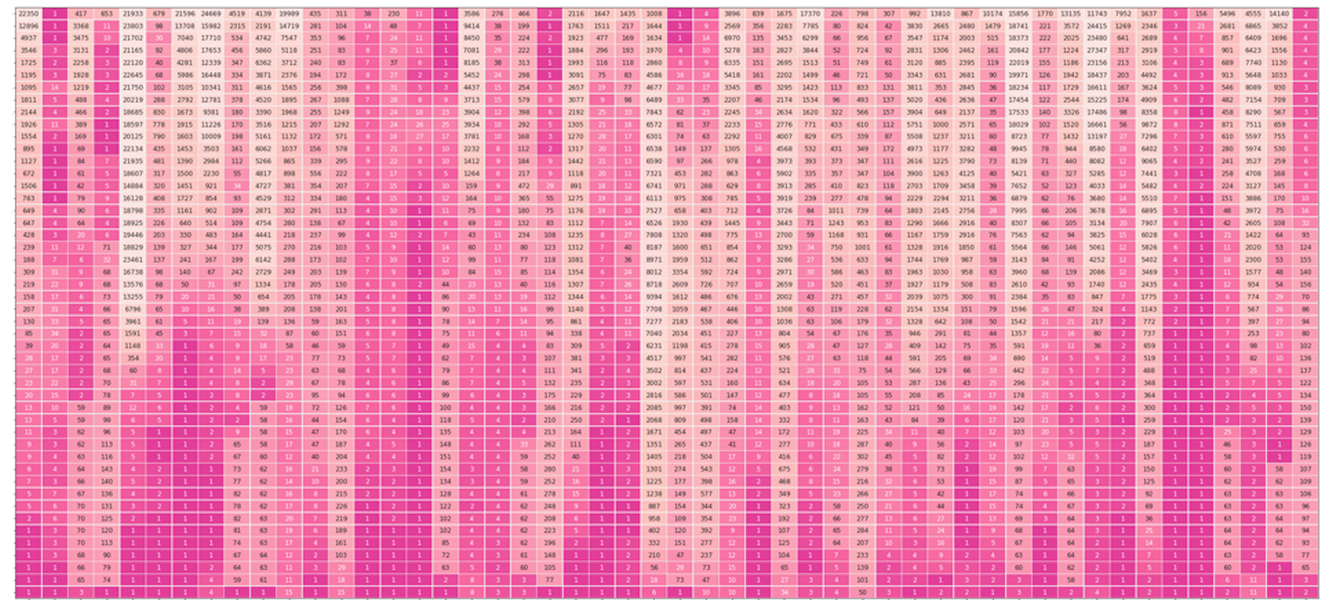
1.5.1 Scores after each layer
下图演示了基于transfromer的语言模型是如何通过层之间运算来得到隐藏态,以及最终的token是如何映射到此表中并且对其他可能得到的token进行标记分数。例如当输入"1,1,"时,下一个词模型59%确定为"1",以及18%的概率判定是"2"(可能我们在正向计数) ![]()
论文所用的开源代码Ecco 提供了模型得分最高的token以及其他候选token及其概率分数。
# Generate one token to complete this input string
output = lm.generate(" 1, 1, 1,", generate=1)
# Visualize
output.layer_predictions(position=6, layer=5)

另外,除了对于最终结果层的概率分数表示,每一层的输出都会进行概率分数表示 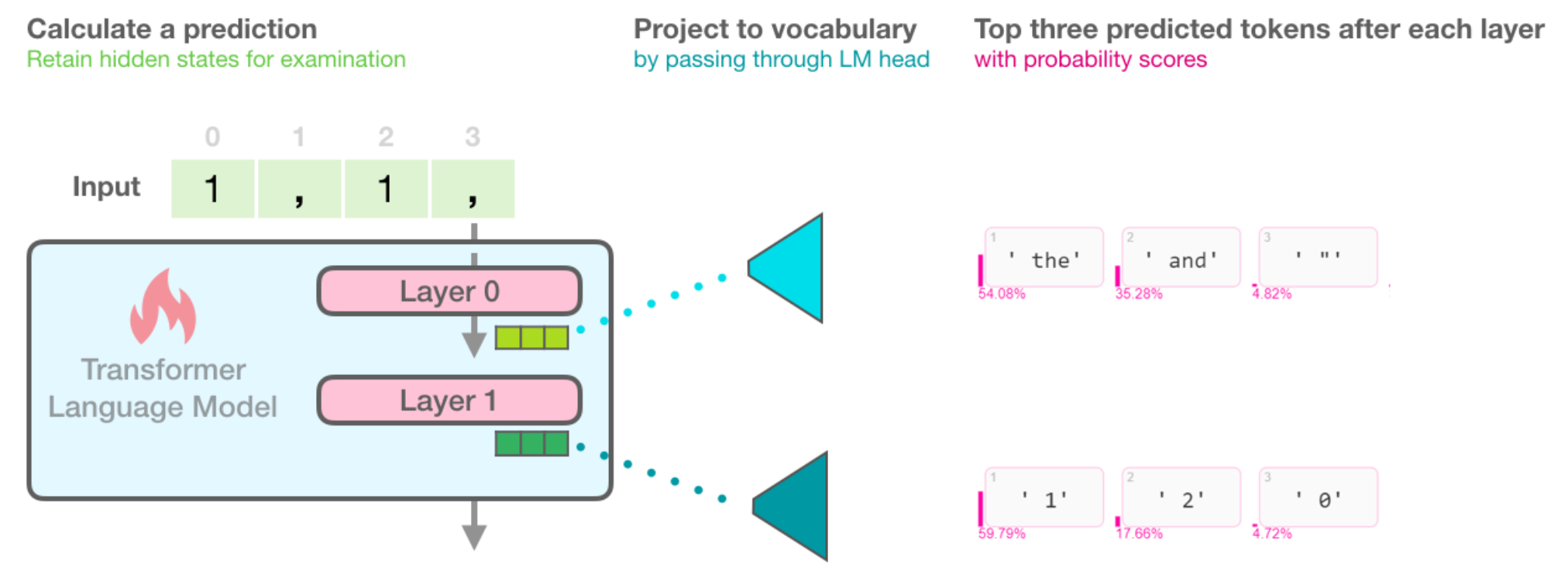
将以上的每层输出概率分数表示进行合并,可以得到一个token概率分数矩阵,如下:(每行通过对隐藏状态投影到词汇表来获取对应的输出词,并将它的logits分数softmax化得到概率分数,这个样例中,第0层前十没有预测数字,第一层"1"也仅仅是0.03的概率,但是后面"1"得到了100%的概率分布,最后一层通过前节提到的参数将概率进行发散,最终定格到了59%的概率分数) 
1.5.2 Evolution of the selected token
另一种可视化是将最终结果的(也就是"1")在每层的排名进行汇总如下: 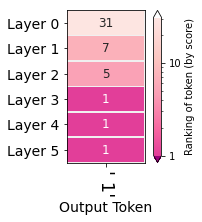 可以看到第0层中"1"在第31位,而从第三层开始排名一直在第一位
可以看到第0层中"1"在第31位,而从第三层开始排名一直在第一位
下面对第二种方法进行拓展,让它来表示之后的输出的累加状态,例如输入"1,1,1," 我们现在来表示输出"1,1"在每层的排名如图: 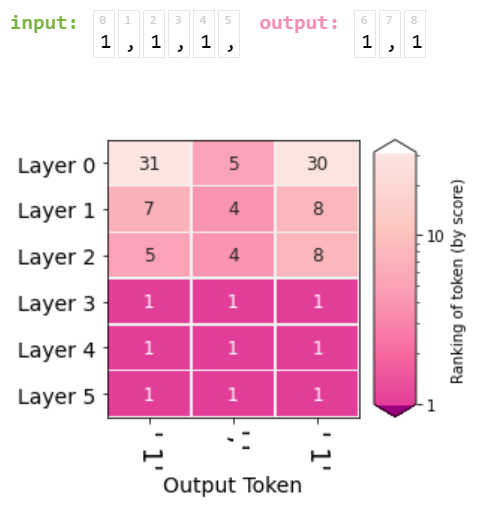
下面对通常的带prompt句子进行演示, 当我们输入:
"The country of the European Union are : \n "
"1 . Austria \n"
"2 . Belgium \n"
"3 . Bulgaria \n"
"4 . "
通过可视化隐藏层可以看到每个层是如何选取词和对于最终输出结果的影响: 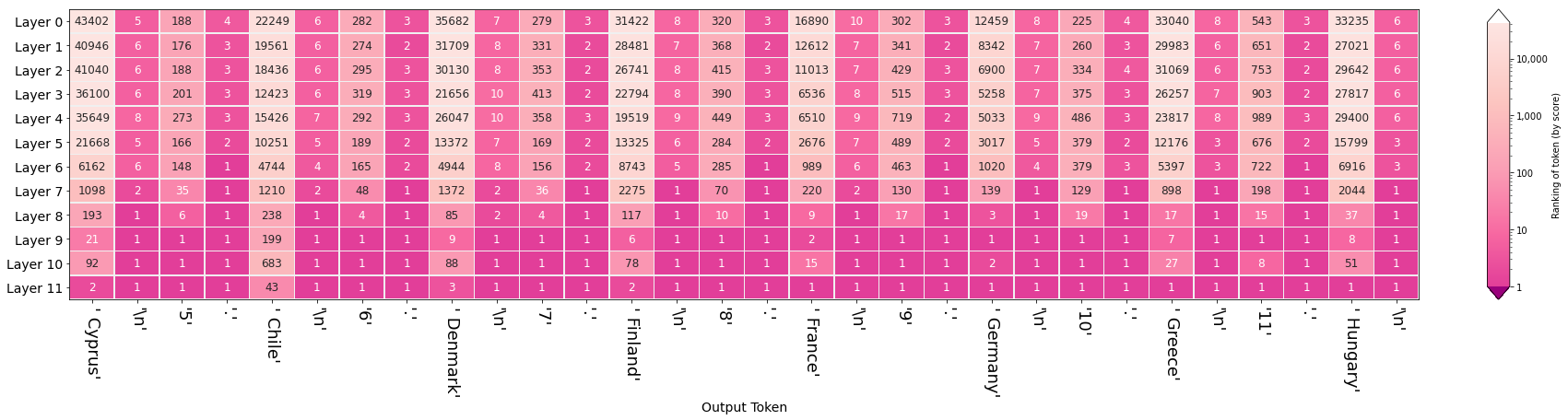
可以看出对于换行符以及句点,模型很早就已经对此进行标记,而且之后没有异议。模型在第九层后,对数字"5" "6"进行了正确的递增预测。值得注意的是:模型错误的将智利列入到欧盟国家中,但是错误的并不是模型本身,因为"chile"在模型预测列表中排名第43,此时应该检查我们上节提到的采样参数来对模型输出进行修改。(另外,除了预测国家外,模型也正确的对国家进行了首字母排序)
1.5.3 Evolution of the selected token
除了对输出token的概率排名演变,我们也希望能够得到其他token的概率演变,例如在对于模型分析单复数和主句对象时,我们可以输入:
"The only acceptable answers are 1) is 2) are"
"The keys to the cabinet __"
来判断模型是否知道我们要表达的主要是keys还是cabinet,确定主语后,再来确定使用"is" 还是 "are" 下图中,可以看到模型对于is还是are的每层概率排名 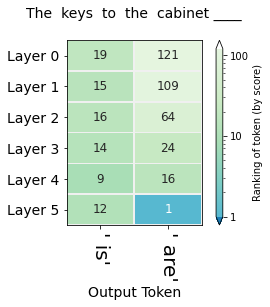 同样的我们可以将题目改成:
同样的我们可以将题目改成:
"The key to the cabinets__"
得到每层的概率排名图: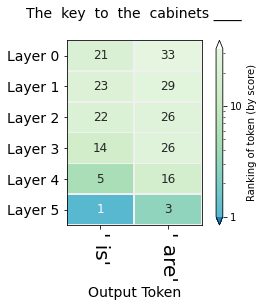
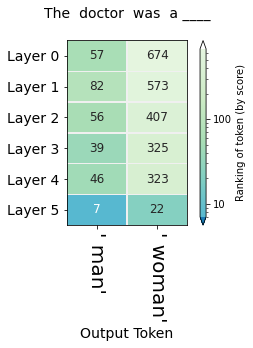
通过上述方法可以探究模型对于偏见现象的产生情况,例如对于不同职业的性别期望