 EgoAlpha
EgoAlpha自我提问
简介
[Aman et al., 2023] 研究通过迭代反馈和改进来精化 LLM 初始输出的框架。主要思想是使用 LLM 生成输出,然后允许同一模型为其自身的输出提供多方面的反馈,最后,同一模型根据自己的反馈改进其先前生成的输出。本文的迭代优化框架不需要监督训练数据或强化学习,并且适用于单个 LLM。我们对评论重写、首字母缩略词生成、故事生成、代码重写、响应生成、约束生成和毒性去除7项不同的任务进行了广泛的实验,证明我们的方法优于直接生成。在所有任务中,使用 SELF-REFINE 生成的输出比直接使用 GPT-3.5 和 GPT-4 生成的输出更受人类和自动化指标的青睐,跨任务平均绝对提高 20%。
原理
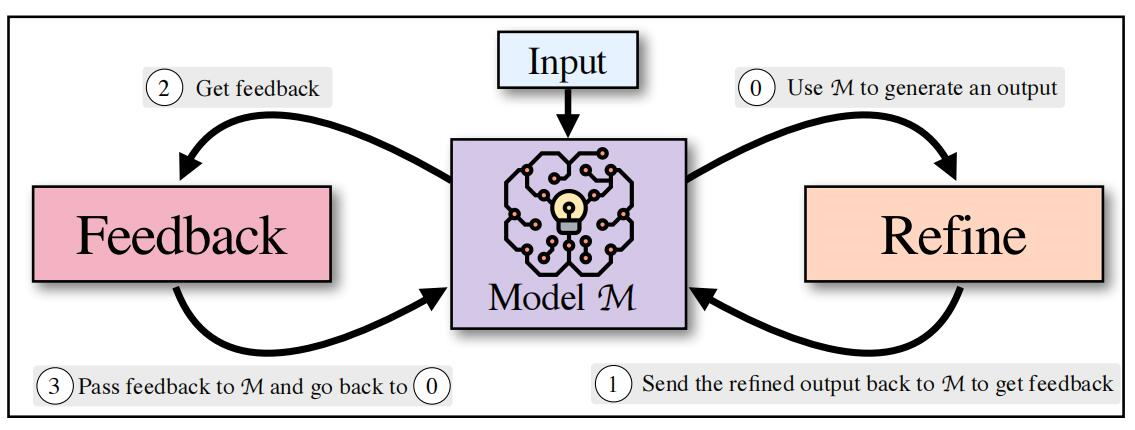 SELF-REFINE由两个组件之间的迭代循环组成:Feedback和Refine,它们协同工作以产生高质量的输出。给定由模型M(0)生成的初始输出,我们将其传递回同一模型M(1)以获得反馈(2)。初始输出的反馈被传递回相同的模型(3),然后迭代地细化(0)先前生成的输出。这个过程会重复指定次数的迭代,或者直到模型本身确定不需要进一步的细化。
SELF-REFINE由两个组件之间的迭代循环组成:Feedback和Refine,它们协同工作以产生高质量的输出。给定由模型M(0)生成的初始输出,我们将其传递回同一模型M(1)以获得反馈(2)。初始输出的反馈被传递回相同的模型(3),然后迭代地细化(0)先前生成的输出。这个过程会重复指定次数的迭代,或者直到模型本身确定不需要进一步的细化。
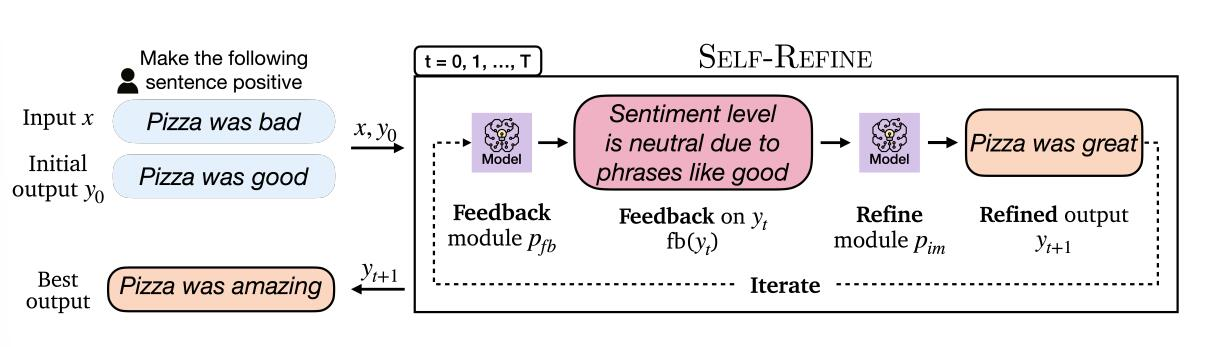 图中是一个应用于情绪逆转的示例。给定一个输入x和一个初始输出y0,SELF-REFINE在一个FEEDBACK→REFINE→FEEDBACK的循环中连续地完善输出。我们假设初始输出y0是由一个生成器模型产生的,它可以是一个专门的微调模型或一个少数的提示模型。例如,对于情感反转的任务,当提供一个输入评论 "比萨饼是坏的 "和一个目标情感是积极的,生成器可能会产生 "比萨饼是好的"。然后,这个输出y0通过SELF-REFINE循环进行迭代改进。
图中是一个应用于情绪逆转的示例。给定一个输入x和一个初始输出y0,SELF-REFINE在一个FEEDBACK→REFINE→FEEDBACK的循环中连续地完善输出。我们假设初始输出y0是由一个生成器模型产生的,它可以是一个专门的微调模型或一个少数的提示模型。例如,对于情感反转的任务,当提供一个输入评论 "比萨饼是坏的 "和一个目标情感是积极的,生成器可能会产生 "比萨饼是好的"。然后,这个输出y0通过SELF-REFINE循环进行迭代改进。
FEEDBACK接收初始输出y0,并提供如何增强它的反馈。此反馈取决于任务,通常涉及输入的多个方面。在给定的例子中,反馈涉及到了情绪水平(“由于良好等短语,情绪是中性的。”)。REFINE负责基于接收到的反馈和先前生成的输出来细化输出yt。在本例中,受“好”等短语引起的评论中性情绪的影响,该模型可能试图通过用“惊人”代替“好”来增强积极性。
 输入x,初始输出y0,反馈模块pfb,改进模块pim,如果t在0到T之间,就进行反馈;如果在这个过程中停止fb score,结束循环;否则,进行refind阶段进行改进,最后输出结果。
输入x,初始输出y0,反馈模块pfb,改进模块pim,如果t在0到T之间,就进行反馈;如果在这个过程中停止fb score,结束循环;否则,进行refind阶段进行改进,最后输出结果。
迭代改进回路可以应用多次。停止标准fb score的定义是:迭代次数可以设置为固定数量(例如,基于预算),也可以是反馈的函数(例如,当反馈是“一切看起来都很好!”时终止,或者当数值fb score分数高于阈值时终止。SELF-REFINE的一个关键方面是保留过去经历的历史。这是通过将以前的输出连续附加到prompt中来实现的。这使系统能够从过去的错误中吸取教训,避免重蹈覆辙。
 该图显示了情绪反转和代码优化任务中的SELF-REFINE示例。
该图显示了情绪反转和代码优化任务中的SELF-REFINE示例。
SELF-REFINE概述:给定初始输出(左),FEEDBACK对其进行评估,并生成纠正所需的可操作反馈(中)。REFINE将反馈考虑在内,并细化输出(右)。例如,在最上面一行,带有负面情绪的初始评论首先转化为正面评论,然后通过反馈进一步细化。(如果你想知道维加斯的魔力消失了去哪里,就看看Trop酒店。用积极的情感来表达)初始输出为(如果你正在拉斯维加斯寻找经济实惠的选择,Trop可能值得考虑),(这篇评论的观点是正面的吗?如果没有,如何改进?)进行反馈,(这篇评论并不正面,因为“值得考虑”等矛盾的措辞),改进之后(如果你正在维加斯寻找一种独特且价格合理的体验,trop可能是你的完美之地。)
代码优化任务中,提供了一个初始代码片段,然后是确定更有效方法的反馈,最后在应用建议的改进后得到优化的代码实现。(编写代码以生成1,2...,N的和)(这个代码很慢,因为它使用暴力算法。更好的方法是使用公式(n(n+1))/2。)

Prompt 示例
Prompt
Concepts: ['animal', 'catch', 'horse', 'lasso', 'ride']
Sentence: The horse catches the lasso and rides on it.
what concepts from the concept list are missing from the sentence?
Concept Feedback: animal
Any feedback on commonsense?
Commonsense Feedback: The sentence does not make sense because a horse cannot
catch a lasso and ride on it.
Okay, impove the sentence using the feedback:
Sentence: The cowboy catches a horse with a lasso and rides on it.
what concepts from the concept list are missing from the sentence?
Concept Feedback: animal
Any feedback on commonsense?
Commonsense Feedback: None
Output
Okay, impove the sentence using the feedback:
Sentence: The cowboy catches the horse with a lasso and rides it.
what concepts from the concept list are missing from the sentence?
Concept Feedback: None
Any feedback on commonsense?
Commonsense Feedback: None
Prompt
Conversation history:
Hi!
Hi there.
What are you listening to?
All sorts of music. I listen when no-one is chatting to me.
That's great!
Thanks.
Do you chat here often?
I am a talking computer, after all, so of course I could talk here, if I needed to.
Let's talk about Taylor Swift!"
response: Sure, Taylor Swift sounds like a good topic.
We want to iteratively improve the provided responses. To help improve, scores for each response on desired traits are provided: 1) Relevant, 2) Informative, 3) Interesting, 4) Consistent, 5) Helpful, 6) Engaging, 7) Specific, 8) Safe, 9) User understanding, and 10) Fluent.
Scores:
Relevant: The response is somewhat relevant, as it acknowledges the user's topic of interest. 2/3
Informative: There is no information provided in the response. 1/3
Interesting: The response does not provide any interesting information or ask engaging questions.
Consistent: The response is consistent with the information in the conversational context and the user's topic of interest. 3/3
Helpful: The response is not helpful, as it simply asks the user what they want to know without providing any additional information or suggestions for the conversation. 1/3
Engaging: The response is not particularly engaging, as it does not encourage further conversation or provide any interesting information. 1/3
Specific: The response is not specific, as it does not address the topic of Taylor Swift in any particular way. 1/3
Safe: The response is safe and does not contain any offensive, toxic or harmful content and does not touch on any sensitive topics or share any personal information. 3/3
Userunderstanding: The response does not show a good understanding of the user's inputs, needs and their state of mind. 1/3
Fluent: The response is fluent in terms of grammar and flow of words. 3/3
total_score: 17/30
response: Sure, what do you like most about her music?
Scores:
Relevant: The response is relevant to the user's topic of interest and asks a specific question related to it. 3/3
Informative: The response provides a relevant question that could prompt the user to share their opinion or knowledge about Taylor Swift's music, potentially leading to an informative conversation. 2/3
Interesting:The response does not provide any interesting information or ask interesting questions. 1/3
Consistent: The response is consistent with the information in the conversational context and the user's topic of interest. 3/3
Helpful: The response is helpful in continuing the conversation and showing interest in the user's topic of conversation but needs to add some information. 2/3
Engaging: The response asks an open-ended question that could potentially lead to a more engaging conversation. 2/3
Specific: The response asks a specific question related to the topic of Taylor Swift's music. 3/3
Safe: The response is safe and does not contain any offensive, toxic or harmful content and does not touch on any sensitive topics or share any personal information. 3/3
Userunderstanding: The response shows a moderate understanding of the user's inputs, needs and their state of mind. 2/3
Fluent: The response is fluent in terms of grammar and flow of words. 3/3
total_score: 24/30
Output
response: Of course! Taylor Swift is known for her incredible songwriting skills. Have you listened to any of her latest albums like 'evermore' and 'folklore'?
Scores:
Relevant: The response is highly relevant to the user's topic of interest, providing information about Taylor Swift's songwriting skills and asking about her latest albums. 3/3
Informative: The response provides information about Taylor Swift's music and introduces the user to her latest albums, potentially leading to an informative conversation. 3/3
Interesting: The response highlights Taylor Swift's songwriting skills, which could spark interest and encourage the user to engage in a deeper discussion about her music. 3/3
Consistent: The response is consistent with the conversational context and the user's topic of interest. 3/3
Helpful: The response is helpful in continuing the conversation and showing interest in the user's topic of conversation. 3/3
Engaging: The response asks a specific and open-ended question about Taylor Swift's latest albums, which could potentially lead to a more engaging conversation. 3/3
Specific: The response asks a specific question about Taylor Swift's latest albums, indicating the system's knowledge of her music. 3/3
Safe: The response is safe and does not contain any offensive, toxic or harmful content and does not touch on any sensitive topics or share any personal information. 3/3
Userunderstanding: The response shows a good understanding of the user's inputs, needs and their state of mind. 3/3
Fluent: The response is fluent in terms of grammar and flow of words. 3/3
total_score: 30/30
数据集
FED
一个人类系统和人类对话的集合,在回合和对话级别都有18个细粒度的对话质量注释。创建该数据集是为了评估交互式对话系统,而不依赖于参考响应或训练数据。
PIE
一个广泛用于代码优化的数据集,旨在测试模型提高Python代码效率的能力,数据集来源于论文,该数据集主要目标是通过实现算法修改来优化给定的程序,从而提高运行时性能。
CodeNet
一个广泛用于代码可读性改进的数据集,旨在测试模型重构代码并提高代码可读性的能力,数据集来源于论文,该数据集都是一些难以阅读的多行代码片段。
GSM-8k
一个广泛用于数学推理任务的数据集,旨在测试模型在解决数字推理方面的能力。
参考文献
[1] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022a. Training a helpful and harmless assistant with reinforcement learning from human feedback.
[2] Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023. Gptscore: Evaluate as you desire.
[3] Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2022. Pal: Program-aided language models.