 EgoAlpha
EgoAlphaiPrompt: Explaining Data Patterns in Natural Language via Interpretable Autoprompting
简介
Chandan Singh et al., 2023本文引入可解释的自动提示(iPrompt),这是一种生成解释数据的自然语言字符串的算法。
换一句话说,iPrompt是一种扩展的AutoPrompt,相较于AutoPrompt,iPrompt生成的文本提示使用自然语言书写以生成语义上有意义的自然语言提示解释数据的一个关键特征,让用户更好理解,具有较强的泛化性。
iPrompt使用经过预训练的冻住的LLM迭代地提出和评估不同的候选解释,并根据它们作为提示符时的表现对它们进行重新排序,从而生成数据集的固定自然语言模型。
从综合数学到自然语言理解,在广泛的数据集上进行的实验表明,iPrompt可以通过准确地找到人类可以解释的数据集来产生有意义的见解。
原理
iPrompt是一种迭代局部搜索算法,在三个步骤之间交替:(1)提出候选提示,(2)重新排列候选提示,以及(3)探索
第一步:提出候选提示
(1) 建议:通过扩展零样本LLM生成生成候选提示。给定一个数据实例作为前缀,我们对一些候选提示进行采样。每个候选者的最大长度是预先指定和固定的。
第二步:重新排列候选提示
(2)重新排序:给定候选项,对每个候选项提示s评估目标等式(1)。保留最大化目标的前几个候选项,例如将候选项缩小到f组合数字、求和或-。
第三步:探索
(iii)反复探索:重新排序的每个排名靠前的候选人都在一个随机位置被截断。当通过后缀解码生成新的候选提示时,这些被截断的候选被用作前缀。例如,我们可以随机选择前面候选者的开头,并填写结尾: {Combine the__, Sum__} ——>{Combine the numbers, Combine both arguments, Sum the numbers, Sum all inputs}.
第四步:重复该算法
重复该算法,直到识别出合适的s^。
Prompt 示例: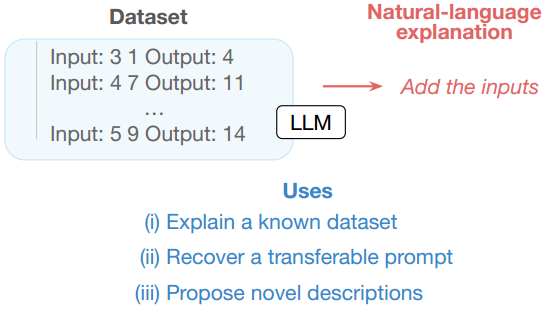
数据集
Synthetic math
需要根据数字输入和输出推断出基本数学函数的数据集。
ANLI
对抗性自然语言推理(ANLI,Nie et al.)是一个新的大规模NLI基准数据集,通过迭代的、对抗性的人类和模型在环过程收集。特别是,选择的数据对于最先进的模型来说是困难的,包括BERT和RoBERTa。
Instruction induction
具有易于验证的描述的多样化语言任务(例如,找到一个国家的首都)。
Sentiment Dataset
一个不同领域的情感分类数据集的集合,不同领域的情感分类数据集。
参考文献
图文、代码详解BeamSearch.[在线].知乎.取自:https://zhuanlan.zhihu.com/p/460733009