 EgoAlpha
EgoAlphaSuccessive Prompting
Introduction
Answering complex questions that involve making implicit decisions is a difficult task, especially when there is limited training data available. Recent studies have utilized large language models to perform complex question answering in a few-shot learning setting, where intermediate reasoning steps are generated and solved in a single pass. [Dua et.al, 2022] introduces a new approach called "Successive Prompting" that iteratively decomposes complex questions into simpler ones, solves them, and repeats the process until arriving at the final solution. Successive Prompting enables the separation of supervision for question decomposition and question answering, allowing us to (1) have multiple opportunities to query incontext examples at each reasoning step (2) learn question decomposition separately from question answering, including using synthetic data, and (3) use bespoke (fine-tuned) components for reasoning steps where a large LM does not perform well.
The authors also propose a method for generating synthetic data to bootstrap the model's ability to decompose and answer intermediate questions. The proposed model achieves an improvement of ∼5% absolute F1 on a few-shot version of the DROP dataset when compared to state-of-the-art models with the same supervision.
How it Works?
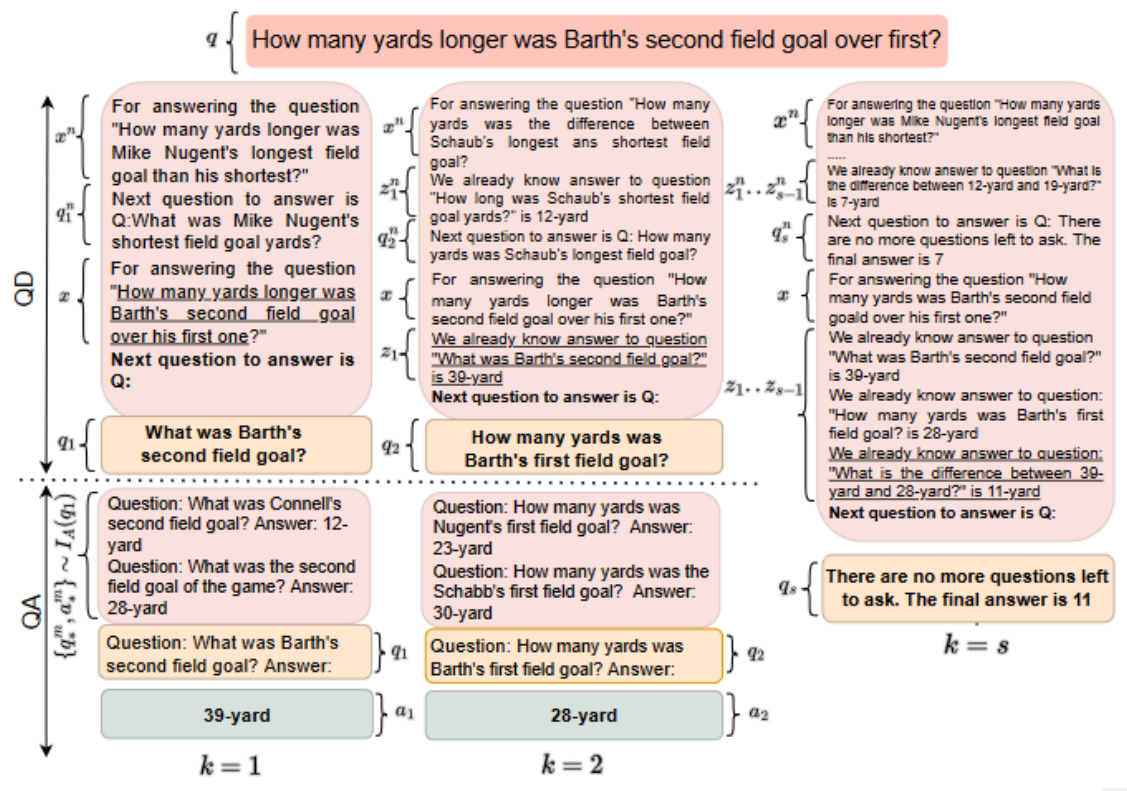
Successive Prompting proposes a way to break down complex questions into simpler ones, answer them separately, and repeat until the complex question is fully answered. we represent each latent step as a pair of simple question and answer, z_k=(q_k,a_k) unlike CoT which represents each latent step as a declarative sentence. we separate z into multiple question and answering steps, which gives us many opportunities to prompt L, with potentially different in-context examples that are more tailored to the simple question at each step. It also enables us to re-encode the context given the intermediate state z_k. We refer to the first kind of output as question decomposition (QD) and the second kind as question answering (QA). We treat final answer prediction as a special case of question decomposition, where the model decides that no more decomposition is necessary and outputs a final answer, so we iteratively alternate between question decomposition and question answering until the model terminates.
During in-context learning, a small number of training examples are provided directly in the prompt that is given to a large LM, before the test input. These examples are selected from an index based on their similarity with the test input. For successive prompting, we create two indices: I_D, for looking-up relevant demonstrations for QD, and I_A, for looking-up relevant demonstrations for QA. The index I_D contains partially decomposed chains at each step k, demonstrating the next question q_k to be produced for every complex question in the training data. The index I_A contains all the simple QA pairs in the training data from all the complex questions.
In the QD stage, the index I_D is queried with the complex test question, q and current step number, k, to select demonstrations regarding how to generate the next question for the held-out example. In the QA stage, the index IA is queried with the simple question q_k generated during QD to select relevant simple QA pairs.
Prompt Example
Prompt
Q: Who threw the longest touchdown pass?
Q1: What are all the touchdown passes?
A1: 22-yard, eight-yard.
Q2: What is the largest value in: 22-yard, eight-yard?
A2: 22- yard.
Q3: Who threw the 22-yard touchdown pass?
A3: Peyton Manning.
Q: There are no more questions left to ask.
Output
Peyton Manning.
Datasets
DROP
A widely used dataset for question answering and reading comprehension tasks, designed to test models' ability in multi-step reasoning and numerical reasoning. The dataset is sourced from Wikipedia articles and question-answering websites. Each sample consists of a paragraph and a question related to the paragraph, and some questions require multi-step reasoning and analysis to arrive at the answer.
QQ-P
A commonly used dataset for the task of question pair matching, aiming to determine whether two questions have similar semantic meanings. The dataset is sourced from the Quora community and includes a large number of non-duplicate question pairs and a portion of duplicate question pairs.
References
[1] Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. 2018. Don’t just assume; look and answer: Overcoming priors for visual question answering. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 4971–4980. IEEE Computer Society.
[2] Daniel Andor, Luheng He, Kenton Lee, and Emily Pitler. 2019. Giving BERT a calculator: Finding operations and arguments with reading comprehension. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5947– 5952, Hong Kong, China. Association for Computational Linguistics.
[3] Xinyun Chen, Chen Liang, Adams Wei Yu, Denny Zhou, Dawn Song, and Quoc V. Le. 2020. Neural symbolic reader: Scalable integration of distributed and symbolic representations for reading comprehension. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net